From Copy-Paste to Competitive Edge: Unlocking Efficiency with Data Portability
The key to origination, underwriting, and lending efficiency in 2025: a data activation layer that make an existing tech stack behave like 1 system, not 10.
The key to origination, underwriting, and lending efficiency in 2025: a data activation layer that make an existing tech stack behave like 1 system, not 10.
Back in 2003, the average loan officer closed 100+ loans a year.
Today?
Just 28.
Even with better lending tech, smarter tools, and more “systems,” output has collapsed.
Why?
I just got back from 2 eventful days in Chicago with 100+ of our community bank investors at the BankTech Ventures Summit, where I hosted a fireside talk with a good friend of SOLO, Tim Heilman, the Chief Innovation Officer of Choice Bank.

Tim and I aren’t traditional bankers.
I’m a data scientist who built a fintech lending platform before founding SOLO.
Tim led the BAAS fintech side of Choice Bank—and scaled it 100x over the last decade.
But the other side of the bank throughout that same time period? They worked with the same tech stack as Tim's team, and yet they couldn’t scale.
Why?
What works for fintechs breaks inside banks. Tim and I both experienced this from different vantage points. Here's what I mean:
With fintech you add APIs, connect new tools, and lending velocity increases as expected.
In banks, every new system becomes another silo. Instead of scaling loan growth every new integration instead spawns a new Chief Copy-and-Paste Officer—someone stuck re-keying the same customer data into five different systems.
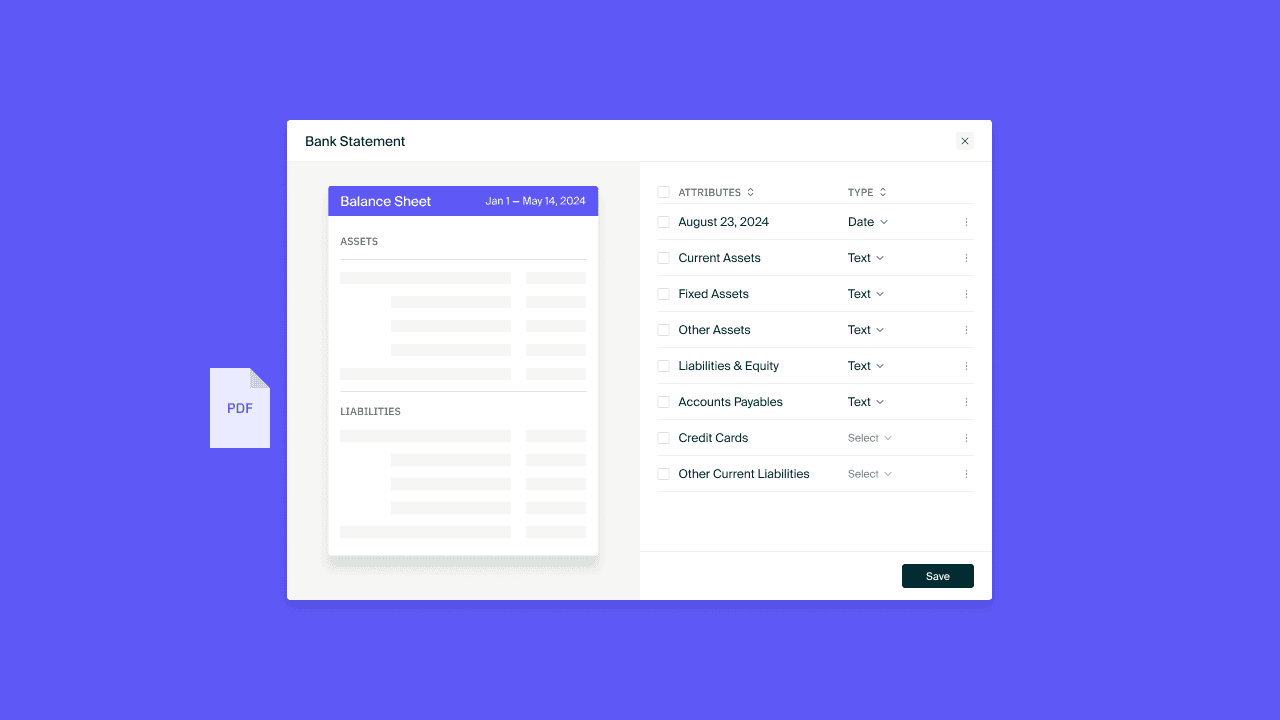
Someone—usually your specialized credit talent—is stuck translating PDFs, spreadsheets, and emails into your workbook. And your LOS. And your CRM. For every system in between, every time your customer needs something.
In theory, we live in a digital world. If you’re a small business, your data lives in QuickBooks. If you’re a consumer, it’s in your payroll platform. But here’s the real problem: it’s not that you don’t have the data—it’s that it lives everywhere.
You already have everything your customers could possibly give you —but your stack can’t reuse it. So it means nothing.
Some of the data underwriters need is in Equifax. Some in Experian. Some in an API feed. Some in a scanned PDF. Some in a document the customer gave you at account opening. And way too much of it is buried in email threads between your borrower and your RM.
You already have what you need to approve or cross-sell—but it’s spread across ten systems and five inboxes. So what happens?
You ask the borrower for it again.
I really like Tim's analogy for how this plays out for our borrowers in the equation:
"It's like calling customer support to start a return at Amazon, then being put on hold, getting redirected, explaining the return all over again to another person, getting redirected to someone else, and the process repeating again and again. Even though Amazon already owns all your data and knows everything about you, you're still the one having to explain."
If this sounds familiar you likely don’t have a data scarcity problem. You don't need another LOS. You have a fragmentation problem.
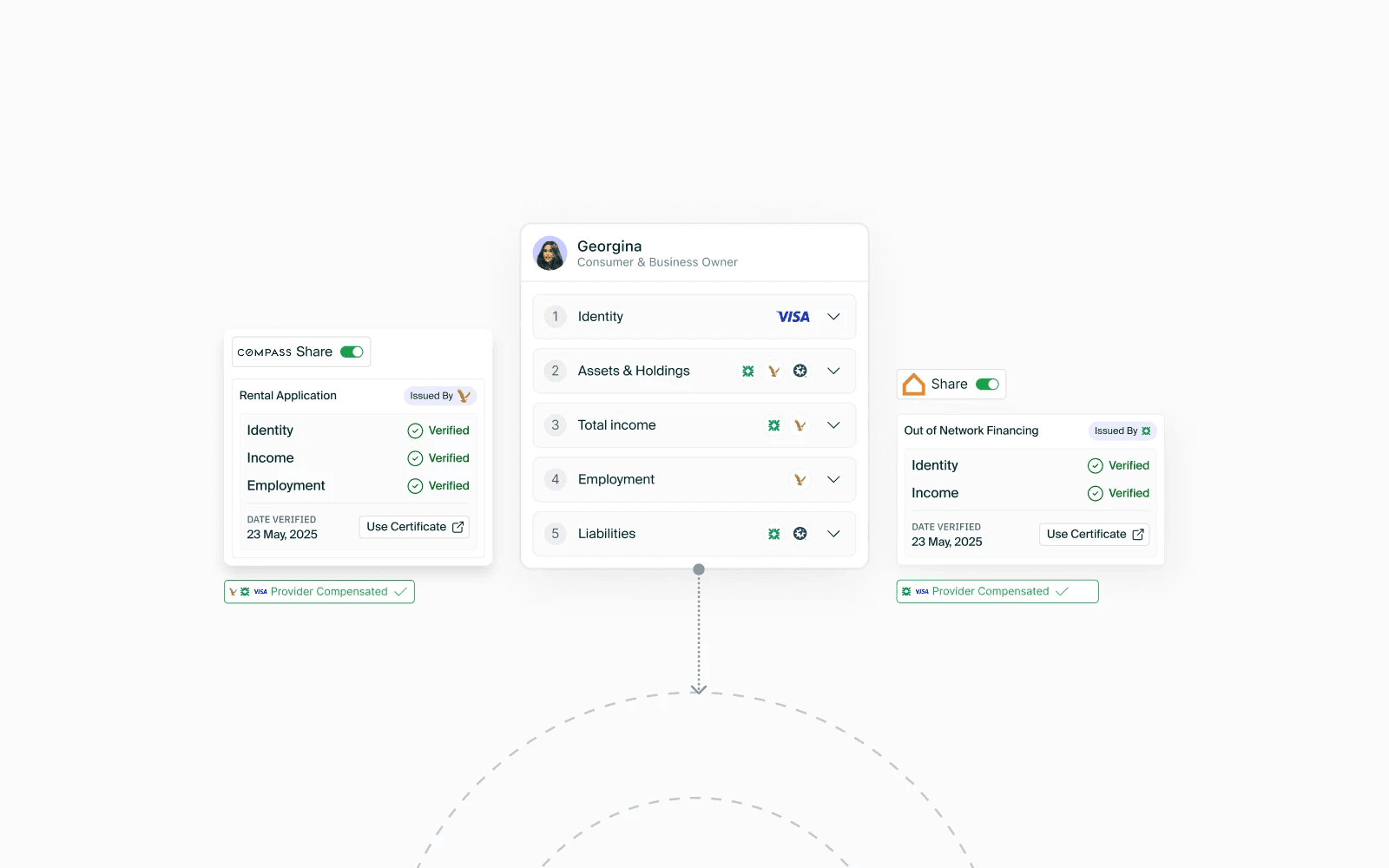
The solution? Not another LOS, but data portability: the ability to access and leverage data from the moment you receive it, for every system and context of decision making. Without manual re-entry to do so.
The biggest threat to this is the lifeline of traditional lending: documents.
Tim, along with a number of other credit and risk leaders we've worked with in the BankTech Ventures portfolio, guided us with the critical perspective we needed when we set out to develop our solution.
We first created a platform that ran off APIs, connecting into real time data sources for lending decisions. But we quickly It's not enough to make lending tech that scales the way a fintech would.
Banks don't need another form builder.
They don’t need to force borrowers into digital portals and pray they'll log in to their accounts.
Banks need the glue.
It's why we engineered SOLO to be the orchestration layer that makes an existing bank tech stack behave like one system—not ten.
With documents working as effectively as an integration to a dynamic data source. That means your tax returns, 1003s, appraisals, spreadsheets—they all become structured, actionable data.
What that looks like in a few different contexts:
If your team is drowning in data entry, if your borrowers are re-introducing themselves over and over, and if your margins are thinning while your tech stack grows—you don’t need more tools. You need data that moves.
One intake, reused across every product and process. No re-asking. No re-keying. No delays.
Here's what we're seeing as a result of data portability on document-driven credit products:
To us, the impacts are clear. Data portability is how you scale without adding headcount. This is how you unlock cross-sell without starting from scratch. This is how you protect your margins while growing.
The end state goal: If your borrower applied once, you should never ask for that info again.
The only way to compete with fintech velocity is to make your stack as responsive as theirs, without compromising on the well honed process that makes banks stand the test of time as the most trusted (and soon, most efficient) players in lending.